Introduction
Apache Hive is an enterprise data warehouse system used to query, manage, and analyze data stored in the Hadoop Distributed File System.
The Hive Query Language (HiveQL) facilitates queries in a Hive command-line interface shell. Hadoop can use HiveQL as a bridge to communicate with relational database management systems and perform tasks based on SQL-like commands.
This straightforward guide shows you how to install Apache Hive on Ubuntu 20.04.

Prerequisites
Apache Hive is based on Hadoop and requires a fully functional Hadoop framework.
Note: If your system does not have a working Hadoop installation, install Hadoop on Ubuntu and only then proceed to install and configure Hive.
Install Apache Hive on Ubuntu
To configure Apache Hive, first you need to download and unzip Hive. Then you need to customize the following files and settings:
- Edit .bashrc file
- Edit hive-config.sh file
- Create Hive directories in HDFS
- Configure hive-site.xml file
- Initiate Derby database
Step 1: Download and Untar Hive
Visit the Apache Hive official download page and determine which Hive version is best suited for your Hadoop edition. Once you establish which version you need, select the Download a Release Now! option.
The mirror link on the subsequent page leads to the directories containing available Hive tar packages. This page also provides useful instructions on how to validate the integrity of files retrieved from mirror sites.
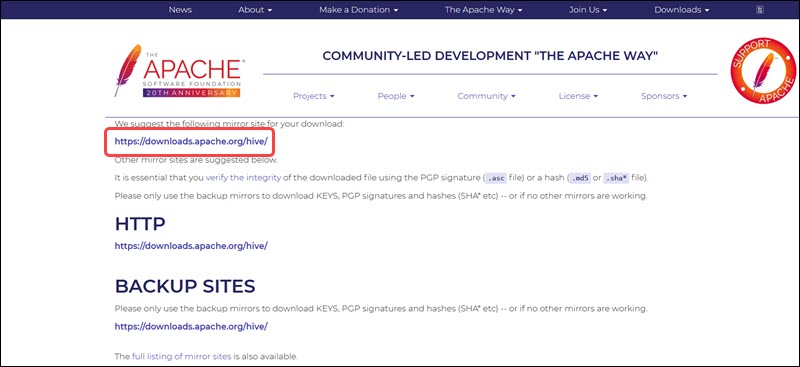
The Ubuntu system presented in this guide already has Hadoop 3.2.1 installed. This Hadoop version is compatible with the Hive 3.1.2 release.
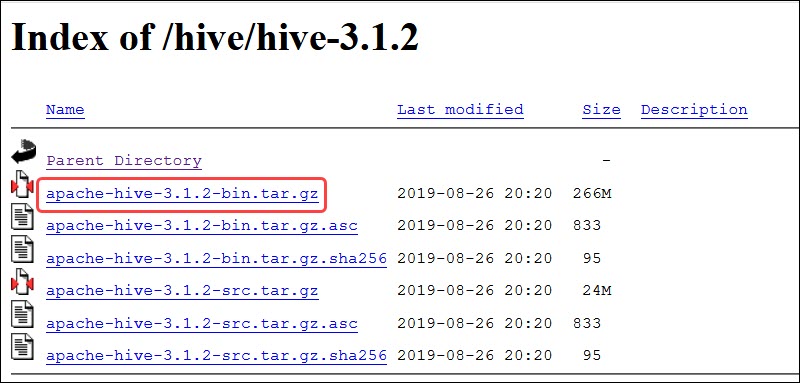
Select the apache-hive-3.1.2-bin.tar.gz file to begin the download process.
Alternatively, access your Ubuntu command line and download the compressed Hive files using and the wget command followed by the download path:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz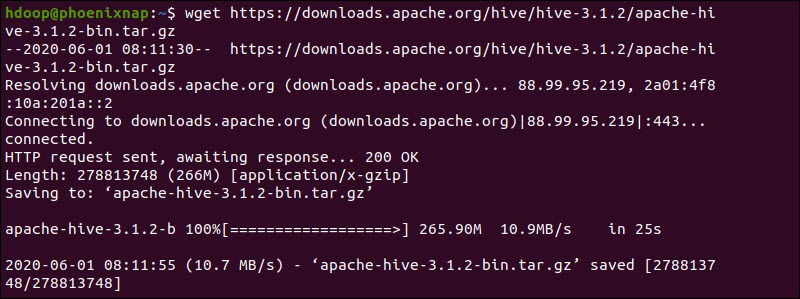
Once the download process is complete, untar the compressed Hive package:
tar xzf apache-hive-3.1.2-bin.tar.gzThe Hive binary files are now located in the apache-hive-3.1.2-bin directory.

Step 2: Configure Hive Environment Variables (bashrc)
The $HIVE_HOME environment variable needs to direct the client shell to the apache-hive-3.1.2-bin directory. Edit the .bashrc shell configuration file using a text editor of your choice (we will be using nano):
sudo nano .bashrcAppend the following Hive environment variables to the .bashrc file:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binThe Hadoop environment variables are located within the same file.
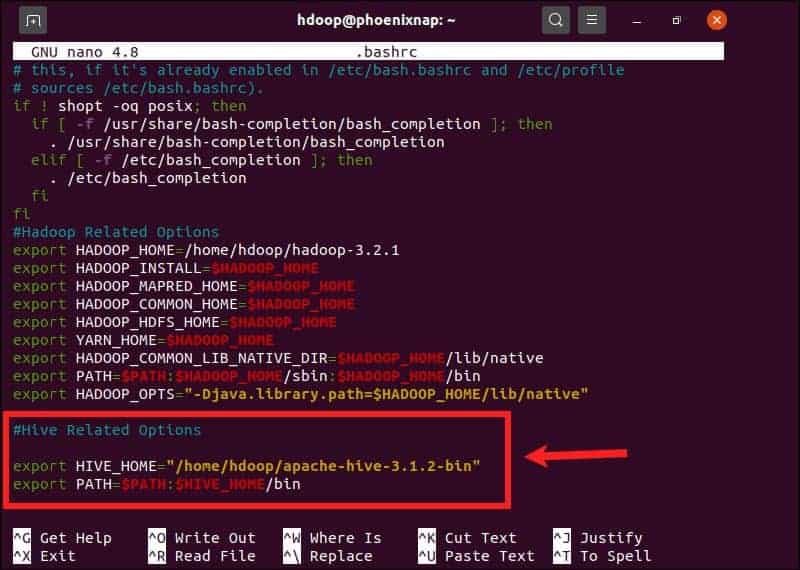
Save and exit the .bashrc file once you add the Hive variables. Apply the changes to the current environment with the following command:
source ~/.bashrcStep 3: Edit hive-config.sh file
Apache Hive needs to be able to interact with the Hadoop Distributed File System. Access the hive-config.sh file using the previously created $HIVE_HOME variable:
sudo nano $HIVE_HOME/bin/hive-config.shNote: The hive-config.sh file is in the bin directory within your Hive installation directory.
Add the HADOOP_HOME variable and the full path to your Hadoop directory:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Save the edits and exit the hive-config.sh file.
Step 4: Create Hive Directories in HDFS
Create two separate directories to store data in the HDFS layer:
- The temporary, tmp directory is going to store the intermediate results of Hive processes.
- The warehouse directory is going to store the Hive related tables.
Create tmp Directory
Create a tmp directory within the HDFS storage layer. This directory is going to store the intermediary data Hive sends to the HDFS:
hdfs dfs -mkdir /tmpAdd write and execute permissions to tmp group members:
hdfs dfs -chmod g+w /tmpCheck if the permissions were added correctly:
hdfs dfs -ls /The output confirms that users now have write and execute permissions.

Create warehouse Directory
Create the warehouse directory within the /user/hive/ parent directory:
hdfs dfs -mkdir -p /user/hive/warehouseAdd write and execute permissions to warehouse group members:
hdfs dfs -chmod g+w /user/hive/warehouseCheck if the permissions were added correctly:
hdfs dfs -ls /user/hiveThe output confirms that users now have write and execute permissions.

Step 5: Configure hive-site.xml File (Optional)
Apache Hive distributions contain template configuration files by default. The template files are located within the Hive conf directory and outline default Hive settings.
Use the following command to locate the correct file:
cd $HIVE_HOME/confList the files contained in the folder using the ls command.

Use the hive-default.xml.template to create the hive-site.xml file:
cp hive-default.xml.template hive-site.xmlAccess the hive-site.xml file using the nano text editor:
sudo nano hive-site.xmlNote: The hive-site.xml file controls every aspect of Hive operations. The number of available advanced settings can be overwhelming and highly specific. Consult the official Hive Configuration Documentation regularly when customizing Hive and Hive Metastore settings.
Using Hive in a stand-alone mode rather than in a real-life Apache Hadoop cluster is a safe option for newcomers. You can configure the system to use your local storage rather than the HDFS layer by setting the hive.metastore.warehouse.dir parameter value to the location of your Hive warehouse directory.
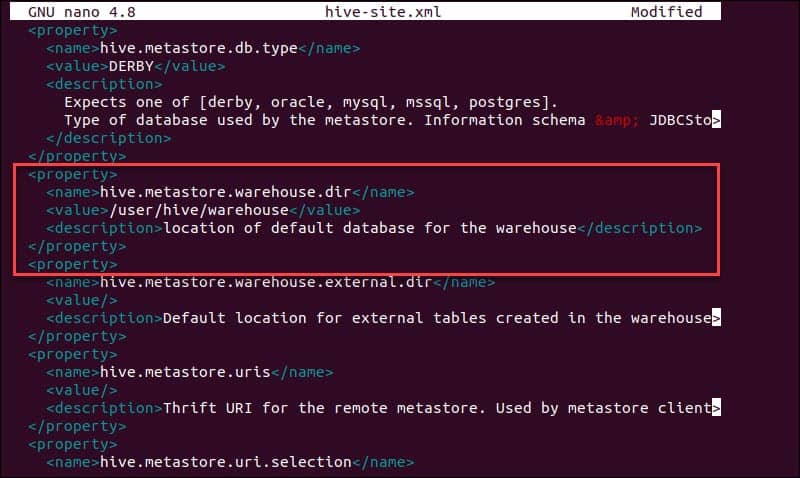
Step 6: Initiate Derby Database
Apache Hive uses the Derby database to store metadata. Initiate the Derby database, from the Hive bin directory using the schematool command:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaThe process can take a few moments to complete.
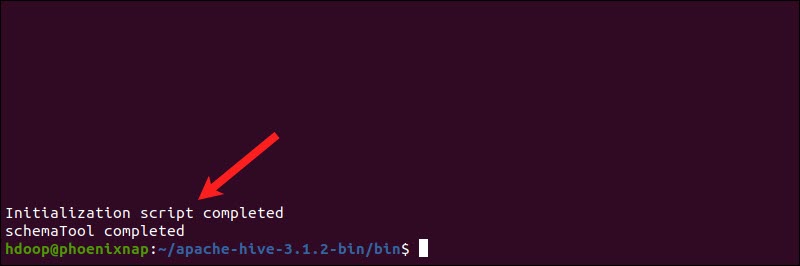
Derby is the default metadata store for Hive. If you plan to use a different database solution, such as MySQL or PostgreSQL, you can specify a database type in the hive-site.xml file.
How to Fix guava Incompatibility Error in Hive
If the Derby database does not successfully initiate, you might receive an error with the following content:
“Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V”
This error indicates that there is most likely an incompatibility issue between Hadoop and Hive guava versions.
Locate the guava jar file in the Hive lib directory:
ls $HIVE_HOME/lib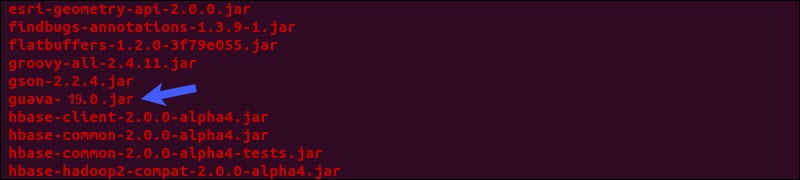
Locate the guava jar file in the Hadoop lib directory as well:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
The two listed versions are not compatible and are causing the error. Remove the existing guava file from the Hive lib directory:
rm $HIVE_HOME/lib/guava-19.0.jarCopy the guava file from the Hadoop lib directory to the Hive lib directory:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/Use the schematool command once again to initiate the Derby database:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaLaunch Hive Client Shell on Ubuntu
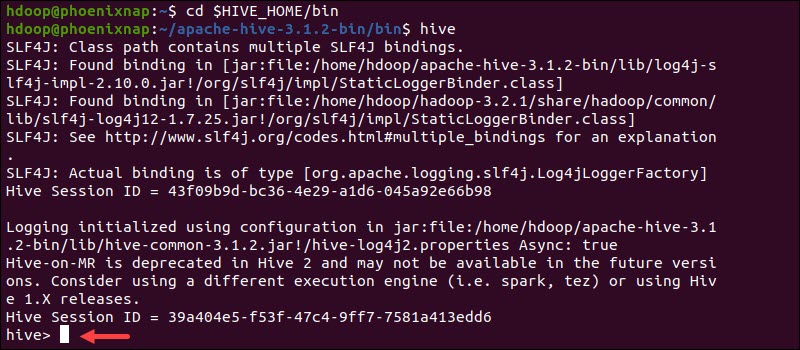
Start the Hive command-line interface using the following commands:
cd $HIVE_HOME/binhiveYou are now able to issue SQL-like commands and directly interact with HDFS.
Conclusion
You have successfully installed and configured Hive on your Ubuntu system. Use HiveQL to query and manage your Hadoop distributed storage and perform SQL-like tasks. Your Hadoop cluster now has an easy-to-use gateway to previously inaccessible RDBMS.
