Introduction
Apache Spark provides three different APIs for working with big data: RDD, Dataset, DataFrame. The Spark platform provides functions to change between the three data formats quickly. Each API has advantages as well as cases when it is most beneficial to use them.
This article outlines the main differences between RDD vs. DataFrame vs. Dataset APIs along with their features.

RDD vs. DataFrame vs. Dataset Differences
The table outlines the significant distinctions between the three Spark APIs:
| RDD | DataFrame | Dataset | |
|---|---|---|---|
| Release version | Spark 1.0 | Spark 1.3 | Spark 1.6 |
| Data Representation | Distributed collection of elements. | Distributed collection of data organized into columns. | Combination of RDD and DataFrame. |
| Data Formats | Structured and unstructured are accepted. | Structured and semi-structured are accepted. | Structured and unstructured are accepted. |
| Data Sources | Various data sources. | Various data sources. | Various data sources. |
| Immutability and Interoperability | Immutable partitions that easily transform into DataFrames. | Transforming into a DataFrame loses the original RDD. | The original RDD regenerates after transformation. |
| Compile-time type safety | Available compile-time type safety. | No compile-time type safety. Errors detect on runtime. | Available compile-time type safety. |
| Optimization | No built-in optimization engine. Each RDD is optimized individually. | Query optimization through the Catalyst optimizer. | Query optimization through the Catalyst optimizer, like DataFrames. |
| Serialization | RDD uses Java serialization to encode data and is expensive. Serialization requires sending both the data and structure between nodes. | There is no need for Java serialization and encoding. Serialization happens in memory in binary format. | Encoder handles conversions between JVM objects and tables, which is faster than Java serialization. |
| Garbage Collection | Creating and destroying individual objects creates garbage collection overhead. | Avoids garbage collection when creating or destroying objects. | No need for garbage collection |
| Efficiency | Efficiency decreased for serialization of individual objects. | In-memory serialization reduces overhead. Operations performed on serialized data without the need for deserialization. | Access to individual attributes without deserializing the whole object. |
| Lazy Evaluation | Yes. | Yes. | Yes. |
| Programming Language Support | Java Scala Python R | Java Scala Python R | Java Scala |
| Schema Projection | Schemas need to be defined manually. | Auto-discovery of file schemas. | Auto-discovery of file schemas. |
| Aggregation | Hard, slow to perform simple aggregations and grouping operations. | Fast for exploratory analysis. Aggregated statistics on large datasets are possible and perform quickly. | Fast aggregation on numerous datasets. |
What is an RDD?
An RDD (Resilient Distributed Dataset) is the basic abstraction of Spark representing an unchanging set of elements partitioned across cluster nodes, allowing parallel computation. The data structure can contain any Java, Python, Scala, or user-made object.
RDDs offer two types of operations:
1. Transformations take an RDD as an input and produce one or multiple RDDs as output.
2. Actions take an RDD as an input and produce a performed operation as an output.
The low-level API is a response to the limitations of MapReduce. The result is lower latency for iterative algorithms by several orders of magnitude. This improvement is especially important for machine learning training algorithms.
Note: Check out our comparison article of Spark vs. Hadoop.
Advantages of RDDs
The advantages and valuable features of using RDDs are:
- Performance. Storing data in memory as well as parallel processing makes RDDs efficient and fast.
- Consistency. The contents of an RDD are immutable and cannot be modified, providing data stability.
- Fault tolerance. RDDs are resilient and can recompute missing or damaged partitions for a complete recovery if a node fails.
When to use RDD
Use an RDDs in situations where:
- Data is unstructured. Unstructured data sources such as media or text streams benefit from the performance advantages RDDs offer.
- Transformations are low-level. Data manipulation should be fast and straightforward when nearer to the data source.
- Schema is unimportant. Since RDDs do not impose schemas, use them when accessing specific data by column or attribute is not relevant.
What are DataFrame and Dataset
A Spark DataFrame is an immutable set of objects organized into columns and distributed across nodes in a cluster. DataFrames are a SparkSQL data abstraction and are similar to relational database tables or Python Pandas DataFrames.
A Dataset is also a SparkSQL structure and represents an extension of the DataFrame API. The Dataset API combines the performance optimization of DataFrames and the convenience of RDDs. Additionally, the API fits better with strongly typed languages. The provided type-safety and an object-oriented programming interface make the Dataset API only available for Java and Scala.
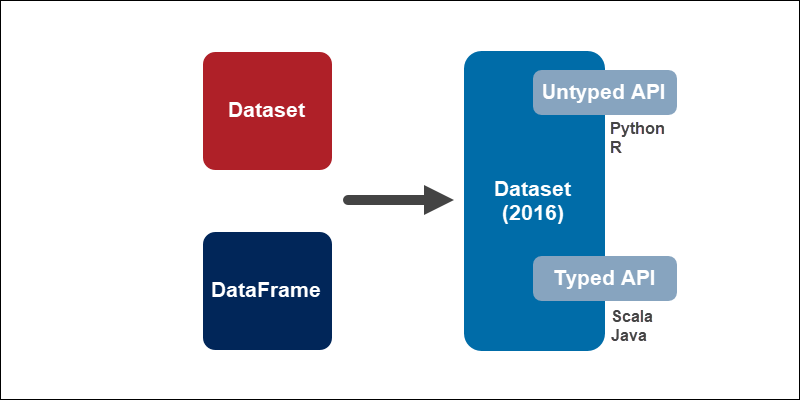
Merging DataFrame with Dataset
In Spark 2.0, Dataset and DataFrame merge into one unit to reduce the complexity while learning Spark. The Dataset API takes on two forms:
1. Strongly-Typed API. Java and Scala use this API, where a DataFrame is essentially a Dataset organized into columns. Under the hood, a DataFrame is a row of a Dataset JVM object.
2. Untyped API. Python and R make use of the Untyped API because they are dynamic languages, and Datasets are thus unavailable. However, most of the benefits available in the Dataset API are already available in the DataFrame API.
Advantages of Dataset
The key advantages of using Datasets are:
- Productive. Compile-time type-safety makes Datasets most productive for developers. The compiler catches most errors. However, non-existing column names in DataFrames detect on runtime.
- Easy to use. A rich set of semantics and high-level functions make the Dataset API simple to use.
- Fast and optimized. The Catalyst code optimizer provides memory and speed efficiency.
When to use Datasets
Use Datasets in situations where:
- Data requires a structure. DataFrames infer a schema on structured and semi-structured data.
- Transformations are high-level. If your data requires high-level processing, columnar functions, and SQL queries, use Datasets and DataFrames.
- A high degree of type safety is necessary. Compile-time type-safety takes full advantage of the speed of development and efficiency.
Note: Learn how to create a Spark DataFrame manually in Python using PySpark.
Conclusion
While RDD offers low-level control over data, Dataset and DataFrame APIs bring structure and high-level abstractions. Keep in mind that transformations from an RDD to a Dataset or DataFrame are easy to execute.
For a more hands-on tutorial, try our Spark Streaming Guide for Beginners to see how RDDs and DataFrames work together for live data streams.
