Introduction
Spark Streaming is an addition to the Spark API for live streaming and processing large-scale data. Instead of dealing with massive amounts of unstructured raw data and cleaning up after, Spark Streaming performs near real-time data processing and collection.
This article explains what Spark Streaming is, how it works, and provides an example use-case of streaming data.

Prerequisites
- Apache Spark installed and configured (Follow our guides: How to install Spark on Ubuntu, How to install Spark on Windows 10)
- Environment set up for Spark (we will use Pyspark in Jupyter notebooks).
- Data stream (we will use Twitter API).
- Python libraries tweepy, json, and socket for streaming data from Twitter (use pip to install them).
What is Spark Streaming?
Spark Streaming is a Spark library for processing near-continuous streams of data. The core abstraction is a Discretized Stream created by the Spark DStream API to divide the data into batches. The DStream API is powered by Spark RDDs (Resilient Distributed Datasets), allowing seamless integration with other Apache Spark modules like Spark SQL and MLlib.
Businesses leverage the power of Spark Streaming in many different use cases:
- Live stream ETL – Cleaning and combining data before storage.
- Continuous learning – Constantly updating machine learning models with new information.
- Triggering on events – Detecting anomalies in real-time.
- Enriching data – Adding statistical information to data before storage.
- Live complex sessions – Grouping user activity for analysis.
The streaming approach allows for faster customer behavior analysis, quicker recommendation systems, and real-time fraud detection. For engineers, any sort of sensor anomaly from IoT devices is visible as the data is collected.
Note: Learn more about the difference between RDD and DataFrame.
Aspects of Spark Streaming
Spark Streaming supports both batch and streaming workloads natively, which provides exciting improvements to data feeds. This unique aspect satisfies the following requirements of modern data streaming systems:
- Dynamic load balance. Since the data divides into micro-batches, bottlenecking is no longer an issue. Traditional architecture processes one record at a time, and once a computationally intense partition comes along, it blocks all other data on that node. With Spark Streaming, the tasks divide among workers, some processing longer and some processing shorter tasks depending on the available resources.
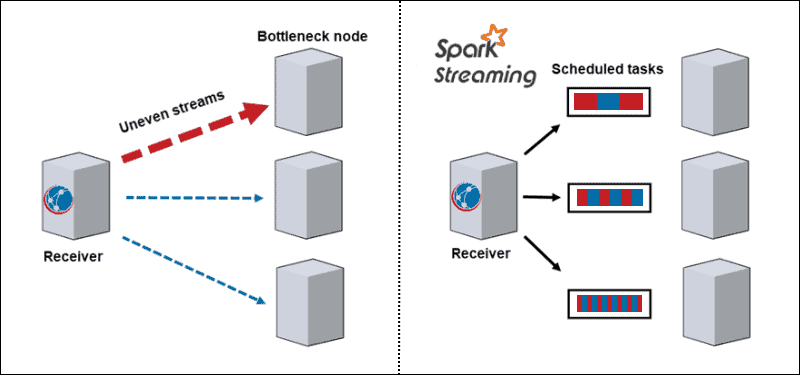
- Failure recovery. Failed tasks on one node discretize and distribute among other workers. While the worker nodes perform computation, the straggler has time to recover.
- Interactive analytics. DStreams are a series of RDDs. Batches of streaming data stored in worker memory query interactively.
- Advanced analytics. The RDDs generated by DStreams convert into DataFrames that query with SQL and extend to libraries, such as MLlib, to create machine learning models and apply them to streaming data.
- Improved stream performance. Streaming in batches increases throughput performance, leveraging latencies as low as a few hundred milliseconds.
Advantages and Drawbacks of Spark Streaming
Every technology, including Spark Streaming, has advantages and drawbacks:
| Pros | Cons |
| Outstanding speed performance for complex tasks | Large memory consumption |
| Fault tolerance | Hard to use, debug and learn |
| Easily implemented on cloud clusters | Not well documented, and learning resources are scarce |
| Multilanguage support | Poor data visualization |
| Integration for big data frameworks such as Cassandra and MongoDB | Slow with small amounts of data |
| Ability to join multiple types of databases | Few machine learning algorithms |
How Does Spark Streaming Work?
Spark Streaming deals with large-scale and complex near real-time analytics. The distributed stream processing pipeline goes through three steps:
1. Receive streaming data from live streaming sources.
2. Process the data on a cluster in parallel.
3. Output the processed data into systems.
Spark Streaming Architecture
The core architecture of Spark Streaming is in discretized streaming of batches. Instead of going through the stream processing pipeline one record at a time, the micro-batches are dynamically assigned and processed. Therefore, the data transfers to workers based on available resources and the locality.
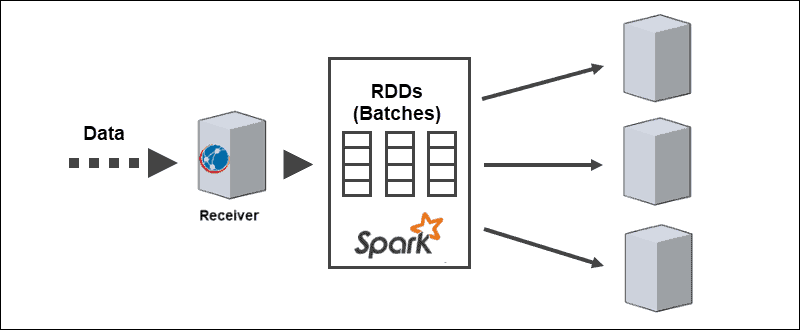
When data arrives, the receiver divides it into partitions of RDDs. Conversion to RDDs allows for processing batches using Spark codes and libraries since RDDs are a fundamental abstraction of Spark datasets.
Spark Streaming Sources
Data streams require data received from sources. Spark streaming divides these sources into two categories:
- Basic sources. The sources directly available in the Streaming core API, such as socket connections and file systems compatible with the HDFS
- Advanced sources. The sources require linking dependencies and are not available in the Streaming core API, such as Kafka or Kinesis.
Each input DStream connects to a receiver. For parallel streams of data, creating multiple DStreams generates multiple receivers as well.
Note: Make sure to allocate enough CPU cores or threads. The receiver uses a share of resources, but processing parallel streamed data also requires computing power.
Spark Streaming Operations
Spark Streaming includes execution of different kinds of operations:
1. Transformation operations modify the received data from the input DStreams, similar to the ones applied to RDDs. The transformation operations evaluate lazily and do not execute until the data reaches the output.
2. Output operations push the DStreams to external systems, such as databases or file systems. Moving to external systems triggers the transformation operations.
Note: The output operations differ depending on the programming language.
3. DataFrame and SQL operations occur when converting RDDs into DataFrames and registering them as temporary tables to perform queries.
4. MLlib operations are used for performing machine learning algorithms, including:
- Streaming algorithms apply to live data, such as streaming linear regression or streaming k-means.
- Offline algorithms for learning a model offline with historical data and applying the algorithm to streaming data online.
Spark Streaming Example
The streaming example has the following structure:
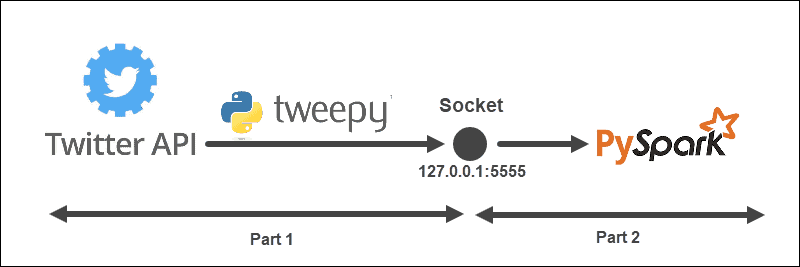
The architecture is split into two parts and runs from two files:
- Run the first file to establish a connection with the Twitter API and create a socket between the Twitter API and Spark. Keep the file running.
- Run the second file to request and start streaming the data, printing processed Tweets to console. Unprocessed sent data prints in the first file.
Create a Twitter Listener Object
The TweetListener object listens for the Tweets from the Twitter stream with the StreamListener from tweepy. When a request is made on the socket to the server (local), the TweetListener listens for the data and extracts the Tweet information (the Tweet text). If the extended Tweet object is available, the TweetListener fetches the extended field, otherwise the text field is fetched. Lastly, the listener adds __end at the end of each Tweet. This step later helps us filter the data stream in Spark.
import tweepy
import json
from tweepy.streaming import StreamListener
class TweetListener(StreamListener):
# tweet object listens for the tweets
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
# Load data
msg = json.loads(data)
# Read extended Tweet if available
if "extended_tweet" in msg:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['extended_tweet']['full_text']+" __end")\
.encode('utf-8'))
print(msg['extended_tweet']['full_text'])
# Else read Tweet text
else:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['text']+"__end")\
.encode('utf-8'))
print(msg['text'])
return True
except BaseException as e:
print("error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return TrueIf any errors occur in the connection, the console prints the information.
Collect Twitter Developer Credentials
The Twitter Developer Portal contains the OAuth credentials to establish an API connection with Twitter. The information is in the application Keys and tokens tab.
To collect the data:
1. Generate the API key & Secret located in the Consumer Keys section of the project and save the information:
The Consumer Keys verify to Twitter your identity, like a username.
2. Generate the Access Token & Secret from the Authentication Tokens section and save the information:
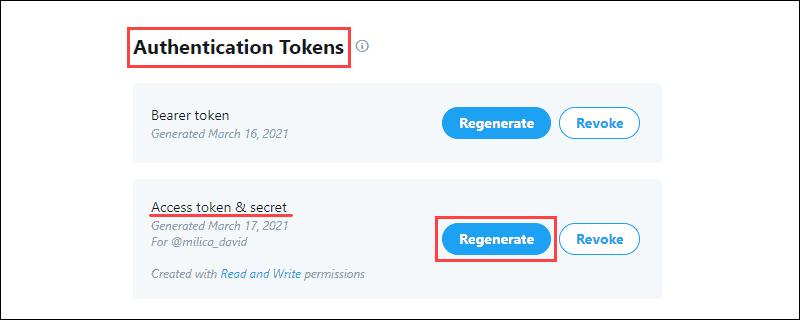
The Authentication Tokens allow pulling specific data from Twitter.
Send Data From the Twitter API to the Socket
Using the Developer credentials, fill out the API_KEY, API_SECRET, ACCESS_TOKEN, and ACCESS_SECRET for accessing the Twitter API.
The function sendData runs the Twitter stream when a client makes a request. The stream request is first verified, then a listener object is created and the stream data filters based on keyword and language.
For example:
from tweepy import Stream
from tweepy import OAuthHandler
API_KEY = "api_key"
API_SECRET = "api_secret"
ACCESS_TOKEN = "access_token"
ACCESS_SECRET = "access_secret"
def sendData(c_socket, keyword):
print("Start sending data from Twitter to socket")
# Authentication based on the developer credentials from twitter
auth = OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Send data from the Stream API
twitter_stream = Stream(auth, TweetListener(c_socket))
# Filter by keyword and language
twitter_stream.filter(track = keyword, languages=["en"])Create Listening TCP Socket on Server
The last part of the first file includes creating a listening socket on a local server. The address and port are bound and listen for connections from the Spark client.
For example:
import socket
if __name__ == "__main__":
# Create listening socket on server (local)
s = socket.socket()
# Host address and port
host = "127.0.0.1"
port = 5555
s.bind((host, port))
print("Socket is established")
# Server listens for connections
s.listen(4)
print("Socket is listening")
# Return the socket and the address of the client
c_socket, addr = s.accept()
print("Received request from: " + str(addr))
# Send data to client via socket for selected keyword
sendData(c_socket, keyword = ['covid'])Once the Spark client makes a request, the socket and address of the client prints to the console. Then, the data stream is sent to the client based on the selected keyword filter.
This step concludes the code in the first file. Running it prints the following information:

Keep the file running and proceed to create a Spark client.
Create a Spark DStream Receiver
In another file, create a Spark context and local streaming context with batch intervals of one second. The client reads from the hostname and port socket.
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="tweetStream")
# Create a local StreamingContext with batch interval of 1 second
ssc = StreamingContext(sc, 1)
# Create a DStream that conencts to hostname:port
lines = ssc.socketTextStream("127.0.0.1", 5555)Preprocess Data
The preprocessing of RDDs includes splitting the received lines of data where __end appears and turning the text into lowercase. The first ten elements print to the console.
# Split Tweets
words = lines.flatMap(lambda s: s.lower().split("__end"))
# Print the first ten elements of each DStream RDD to the console
words.pprint()After running the code, nothing happens since the evaluation is lazy. The computation starts when the streaming context begins.
Start Streaming Context and Computation
Starting the streaming context sends a request to the host. The host sends the collected data from Twitter back to the Spark client, and the client preprocesses the data. The console then prints the result.
# Start computing
ssc.start()
# Wait for termination
ssc.awaitTermination()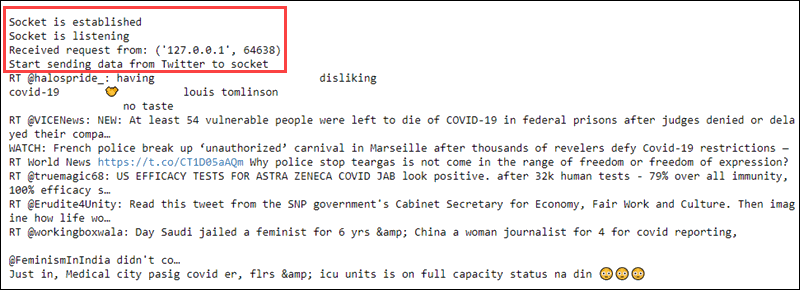
Starting the streaming context prints to the first file a received request and streams the raw data text:
The second file reads the data every second from the socket, and preprocessing applies to the data. The first couple of lines are empty until the connection establishes:
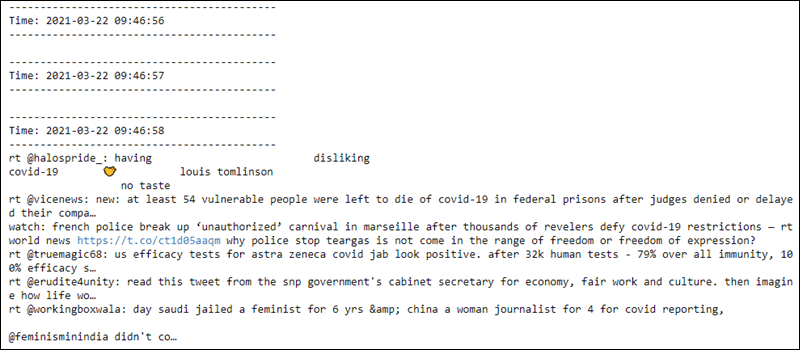
The streaming context is ready to be terminated at any moment.
Conclusion
Spark Streaming is a tool for big data collection and processing. By reading this article you learned how data turns into RDDs, while working with other Spark APIs.
Next, learn about deploying Spark clusters from our article on Automated Deployment of Spark clusters on a Bare Metal Cloud.
